Xe HPC e Ponte Vecchio, Intel vuole scalzare AMD e Nvidia dai supercomputer
Non solo Xe HPG, ma nel corso dell’Architecture Day 2021 Intel ha parlato soprattutto della microarchitettura Xe HPC per accelerare AI, HPC e carichi di lavoro di analisi avanzata e il prodotto che la incarnerà al meglio, Ponte Vecchio. Un Raja Koduri piuttosto franco ha esordito affermando che in casa Intel hanno un problema che si trascinano da quasi 10 anni.

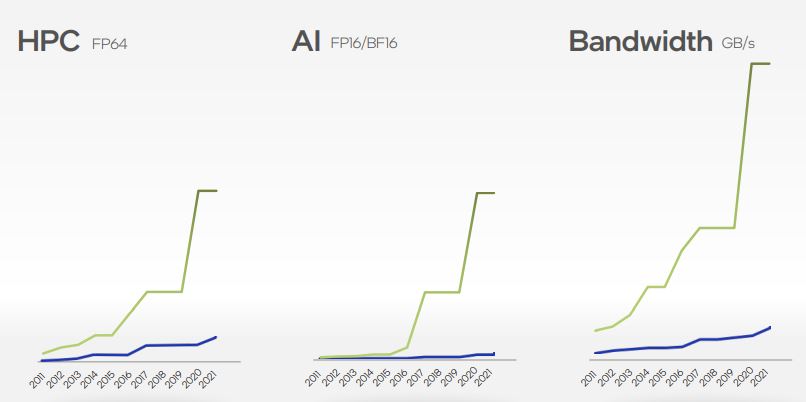
Di che si tratta? Il colosso statunitense è rimasto drammaticamente indietro in termini di throughput e supporto alla memoria ad alta bandwidth rispetto alla concorrenza, due caratteristiche essenziali quando si parla di IA e HPC, e punti dirimenti quando si tratta di GPU. Due grafici illustrano la situazione attuale: la linea blu è Intel, la linea verde il riferimento di mercato. Nel 2017 si è poi aggiunto il calcolo a precisione mista – FP16/BF16 – dedicato all’intelligenza artificiale e “le cose sono andate peggio”, ha aggiunto Koduri (che per inciso si è unito a Intel a fine 2017).
“Vogliamo chiudere questo gap in un colpo solo“, ha spiegato il boss delle architetture di Intel introducendo Xe HPC, il progetto alla base dell’acceleratore Ponte Vecchio. Hong Jiang, chief architect per Xe HPC, ci ha spiegato che l’architettura si basa su quattro blocchi: core, slice, stack e link.


Per quanto riguarda Xe-core, in Xe HPC abbiamo a che fare con un’unità basata su 8 Vector Engine e 8 Matrix Engine (XMX) supportati da un’unità load / store che può eseguire un fetching a 512 byte per clock e un’ampia cache L1 configurabile via software. Questa unità è il blocco base di uno slice, ossia un’unità formata da 16 Xe-core, 8 MB di cache L1 e 16 unità ray tracing, fornendo un solo “hardware context” che permette di eseguire parallelamente più applicazioni senza intoppi, permettendo un uso più efficace della GPU nel cloud.


Salendo a un livello maggiore arriviamo allo stack, che conta 4 Slice per un totale di 64 Xe-core, 64 unità ray tracing unit e 4 hardware context. Completano il tutto un’enorme cache L2, 4 controller HBM2e, un media engine e 8 Xe Link.

L’architettura è però scalabile, quindi Intel può creare design a più stack sfruttando la sua tecnologia di packaging EMIB. Di conseguenza con 2 stack Intel offre 128 Xe-core, 128 unità ray tracing, 8 hardware context, 2 media engine, 8 controller HBM2e e 16 Xe Link, il tutto garantendo la coerenza della memoria tra gli stack. Xe Link è il collegamento che permette una comunicazione ad alta velocità “GPU to GPU” e di collegare in un nodo fino a 8 GPU senza dover ricorrere a componenti esterni.


Ed è qui che si arriva a Ponte Vecchio, l’implementazione concreta di quanto ideato da Intel. Masooma Bhaiwala, chief engineer di Ponte Vecchio, ha affermato che il “chip” è senza dubbio il più complesso che ha mai realizzato in carriera. “Non so nemmeno se possiamo chiamarlo chip, è una collezione di chip che chiamiamo Tile, le quali lavorano insieme grazie a un’interconnessione ad alta bandwidth come una soluzione monolitica”. Ponte Vecchio è un prodotto che ha richiesto a Intel di lavorare da zero su tutti gli aspetti, dalla progettazione alla verifica.


Con oltre 100 miliardi di transistor, 47 tile attive e l’uso di 5 processi produttivi diversi, Ponte Vecchio si compone di Compute Tile, Rambo Tile, Foveros, Base Tile, HBM Tile, Xe Link Tile, Multi Tile Package ed EMIB Tile.

“Ponte Vecchio è composto da diversi elementi complessi che si manifestano in tile, che vengono poi assemblati attraverso una tile EMIB che consente un collegamento a basso consumo e alta velocità tra le tile. Queste sono assemblate nel package Foveros che crea lo stacking 3D di silicio attivo per l’alimentazione e la densità di interconnessione. Un’interconnessione MDFI ad alta velocità consente di aumentare la scalabilità da uno a due stack”, ha spiegato Bhaiwala.

La Compute Tile consta di 8 Xe-core, ha 4 MB di cache L1 ed è prodotta da TSMC con tecnologia N5. La Base Tile, invece, è realizzata con processo Intel 7, occupa un’area di 640 mm2, offre 144 MB di cache L2 e figura un’interfaccia PCI Express 5.0. Infine, Intel ha indicato che la Xe Link Tile è realizzata da TSMC con processo N7.

Il primo chip Ponte Vecchio realizzato e testato da Intel ha dimostrato di poter offrire prestazioni ai vertici del settore, stabilendo record sia in termini di inferenza che di throughput su un benchmark AI di utilizzo comune. Le prestazioni del chip A0 di Intel forniscono un throughput superiore a 45 TFLOPS FP32, una bandwidth del Memory Fabric di oltre 5 TBps e una bandwidth per la connettività maggiore di 2 TBps.


Ponte Vecchio è in produzione con i primi sample, che sono sottoposti alla fase di validazione, ed è partita la fase di sampling limitata verso i clienti. Sarà presentato nel 2022 per i mercati HPC e AI dove Intel sta già preparando l’ecosistema con oneAPI, uno stack software unificato, cross-architecture e cross-vendor, aperto e basato su standard per permettere una programmazione unica capace di funzionare su più architetture di calcolo.
Fonte: http://feeds.hwupgrade.it/