NVIDIA Blackwell B200: due chip in uno per rivoluzionare l’intelligenza artificiale

NVIDIA ha presentato alla GTC 2024 il nuovo le nuove soluzioni B100, B200 e GB200 per accelerare l’intelligenza artificiale. La B sta per Blackwell, in onore del matematico e statistico americano David Blackwell, e descrive l’architettura alla base della GPU che muove i diversi acceleratori.

Jensen Huang mostra Blackwell (a sinistra), confrontandone le dimensioni rispetto a Hopper – clicca per ingrandire
La GPU B100 sarà disponibile solo per i sistemi HGX di terze parti, al fine di integrarsi nei server esistenti grazie a un TDP più contenuto (700W) e prestazioni, di conseguenza, inferiori. Il focus di NVIDIA durante il keynote alla GTC 2024 è stato tutto per B200.
NVIDIA B200 Blackwell: due GPU ne formano una potentissima
La nuova GPU Blackwell B200 è composta da due chip (die) che ne compongono uno solo, prodotti con processo 4NP (una variante ottimizzata dell’N4P) di TSMC. I due chip sono collegati tra loro da un’interfaccia C2C (Chip-to-Chip) con una bandwidth di 10 TB/s, un valore estremamente elevato se si pensa che l’interconnessione UltraFusion delle soluzioni Apple Ultra arriva a 2,5 TB/s.

Clicca per ingrandire
Dal punto di vista produttivo, NVIDIA si è avvalsa della tecnologia di packaging CoWoS-L di TSMC, che, secondo la casa taiwanese, rende teoricamente possibile collegare insieme fino a sei di queste GPU. Secondo NVIDIA, al momento non è prevista una variante della GPU Blackwell con un solo chip, anche se tecnicamente ciascuno dei chip è in grado di funzionare da solo.
Questo profondo cambiamento nel design, con l’addio a un die monolitico per passare a una GPU multi-die, non è inedito nell’industria in quanto la sua introduzione si deve ad AMD con gli acceleratori Instinct MI250X e MI250 nel novembre 2021.
NVIDIA ci ha messo più tempo per passare al progetto MCM rispetto ad AMD, ma si è dovuta adeguare per coniugare la necessità di offrire una potenza elevatissima senza far impennare eccessivamente costi e consumi. Inoltre, produrre una GPU monolitica di dimensioni ancora maggiori rispetto a GH100 avrebbe rappresentato uno sforzo tecnicamente ai limiti dell’impossibile. D’altronde, la forza di un progetto MCM risiede nella maggior flessibilità in fase di progetto, fino ad arrivare alla selezione dei processi produttivi. Il tutto con ricadute anche in termini di temperature e consumi.

Clicca per ingrandire
I due chip che compongono la GPU Blackwell si spingono fino al limite del reticolo e, come tali, occupano un’area di circa 1600 mm2 e sono composti un totale di ben 208 miliardi di transistor, 104 miliardi per chip – 24 miliardi in più rispetto agli 80 miliardi della GPU GH100 Hopper.
Entrambi i chip sono collegati a quattro chip di memoria HBM3E da 24 GB (8-Hi), il che porta il totale a 192 GB di memoria HBM3E per l’acceleratore B100. La bandwidth della memoria HBM3E è pari a 8 TB/s, superiore ai 5 TB/s di GH200 e ai 5,3 TB/s di Instinct MI300X di AMD.

Clicca per ingrandire
Una capacità di memoria di 192 GB di memoria HBM3E rappresenta un incremento importante rispetto agli 80 GB di HBM3 di H100 e ai 141 GB di HBM3E di H200 e GH200, mentre è identico a quello offerto da AMD con l’acceleratore Instinct MI300X, dotato anch’esso di 192 GB di memoria ma di tipo HBM3.
Per quanto riguarda la potenza di calcolo, NVIDIA ha diffuso dati che sono relativi solo ai Tensor Core dell’architettura Blackwell, il che permette di vedere come Blackwell migliori mediamente di 2,5 volte, con punte fino a 5 volte, le prestazioni di Hopper con calcoli a precisione ridotta. Al momento, NVIDIA non ha fornito informazioni sulla potenza di calcolo FP64 delle unità shader o sul loro numero. Insomma, non abbiamo un quadro esaustivo su Blackwell in questo momento.

Clicca per ingrandire
Secondo NVIDIA la GPU Blackwell tocca 20 petaflops in FP4 e 10 petaflops in FP8 tramite i Tensor Core. Per confronto, H100 raggiunge circa 4 petaflops sotto forma di modulo SXM5 con calcoli FP8, 3 petaflops come scheda PCIe e poco meno di 8 petaflops nella configurazione NVL con due GPU. Poiché non è possibile svolgere operazioni FP4 usando i Tensor Core di Hopper, non è possibile un confronto diretto su tale campo.
Fulcro delle maggiori prestazioni è la seconda generazione del Transformer Engine, destinata ad aumentare significativamente il throughput grazie a una precisione di 4 bit che consente il doppio della produttività rispetto all’FP8 senza richiederne la stessa precisione.

Clicca per ingrandire
Come accennato all’inizio, NVIDIA indica per Blackwell un TDP che va da 700 a 1200 W. Le varianti raffreddate ad aria di B100 e B200 hanno un TDP rispettivamente di 700 e 1000 W, mentre il valore di 1200 W appartiene alle soluzioni B200 raffreddate a liquido.

Clicca per ingrandire
Tra le tante particolarità di Blackwell c’è anche la compatibilità con lo standard PCI Express 6.0. Come le precedenti soluzioni, anche Blackwell con le altre GPU grazie a un’interconnessione NVLink capace di toccare ben 1,8 TB/s, il doppio dei 900 GB/s della versione a bordo sugli acceleratori Hopper.
![]()
Clicca per ingrandire
Oltre a B100 e B200, NVIDIA ha messo a punto anche GB200, ovvero Grace Blackwell Superchip, un acceleratore che fonde su un’unica scheda una CPU Grace e due GPU Blackwell. La CPU Grace è identica a quella vista su GH100/GH200, mentre la capacità di memoria combinata è di 864 GB – 2 x 192 GB HBM3E per i due acceleratori Blackwell e 480 GB di memoria LPDDR5X collegati alla CPU Grace.
La connessione tra la CPU Grace e le GPU Blackwell avviene tramite a un’interconnessione bidirezionale NVLink C2C a 900 GB/s. Esternamente, ogni acceleratore GB200 ha un collegamento NVLink bidirezionale a 1,8 TB/s.

Clicca per ingrandire
Durante il keynote, NVIDIA ha parlato anche di GB200 NVL72, un rack raffreddato a liquido al cui interno sono presenti 36 acceleratori GB200 per un totale di 72 GPU e 36 CPU. L’obiettivo di GB200 NVL72 è quello di gestire LLM fino a 27 trilioni di parametri, un numero molto alto considerato che per gli attuali LLM si parla di diversi miliardi di parametri: NVIDIA non vuole farsi trovare impreparata all’avvento dei futuri LLM.
“GB200 NVL72 offre un aumento prestazionale fino a 30 volte rispetto allo stesso numero di GPU NVIDIA H100 Tensor Core per carichi di lavoro di inferenza LLM e riduce i costi e il consumo energetico fino a 25 volte”, afferma la società.
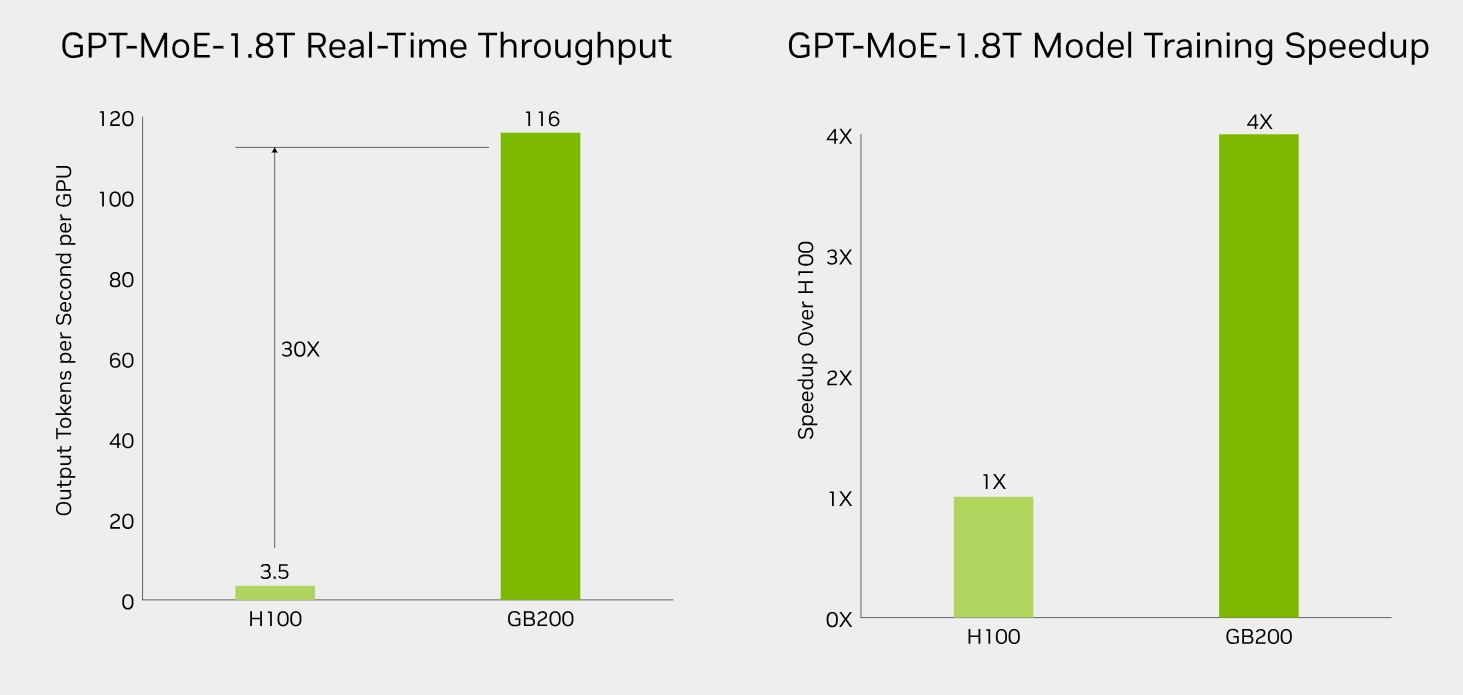
Clicca per ingrandire
Il rack GB200-NVL72 sarà accessibile tramite fornitori di servizi cloud come AWS, Google Cloud, Microsoft Azure e Oracle Cloud. AWS prevede di costruire un supercomputer AI chiamato Ceiba, che sarà basato su GB200-NVL72 per un totale di oltre 20.000 GPU Blackwell e una potenza con calcoli IA superiore a 400 exaflops.
Articolo in aggiornamento…
Fonte: http://feeds.hwupgrade.it/