Instinct MI250 e MI250X, così AMD vuole sverniciare NVIDIA nei settori HPC e IA

MD ha presentato Instinct MI250 e MI250X, i nuovi acceleratori della serie Instinct MI200. Oltre a basarsi sulla nuova architettura CDNA 2, successore della CDNA a bordo della serie Instinct MI100, i due prodotti destinati ad accelerare i calcoli HPC e di intelligenza artificiale sono di assoluta rilevanza perché si basano sulla prima GPU multi-die al mondo.

In base a quanto annunciato da AMD, l’acceleratore Instinct MI250X è in grado di offrire prestazioni fino a 4,9 volte maggiori delle proposte concorrenti (NVIDIA A100 Ampere) nei calcoli HPC a doppia precisione (FP64).
L’acceleratore, inoltre, supera i 380 teraflops con i calcoli half-precision (FP16) tipici del settore dell’intelligenza artificiale, lasciandosi alle spalle NVIDIA A100 del 20%. In pratica, con la nuova serie Instinct, AMD dice di essere riuscita a compiere in 1 anno un balzo prestazionale che finora aveva richiesto 7 anni.

I nuovi acceleratori sono, insieme alle CPU EPYC di terza generazione e alla piattaforma open source ROCm 5.0, il cuore pulsante del nuovo supercomputer Frontier dell’Oak Ridge National Laboratory del Dipartimento dell’Energia statunitense, un sistema capace di raggiungere una potenza di picco superiore a 1,5 exaflops.

Soffermiamoci sulla GPU, una soluzione da 58 miliardi di transistor prodotta con processo a 6 nanometri da TSMC. Come detto, si tratta della prima soluzione al mondo basata su due die (AMD parla di GCD, Graphic Compute Die), ognuno con un massimo di 110 CU: MI250X conta quindi 220 CU per un totale di 14080 stream processor. L’acceleratore offre una potenza di calcolo con calcoli vettoriali FP32/64 di 47,9 TFLOPs e arriva a 383 TOPs con calcoli INT4/8.
| Modello | Compute Unit | Stream processor | FP64 | FP32 Vector (picco) | FP64 | FP32 Matrix (picco) | FP16 | bf16 (picco) | INT4 | INT8 (picco) | HBM2E ECC | Bandwidth memoria |
| AMD Instinct MI250X | 220 (110 x 2) | 14080 | 47,9 TFLOPs | 95,7 TFLOPs | 383 TFLOPs | 383 TOPS | 128 GB | 3,2 TB/s |
| AMD Instinct MI250 | 208 (104 x 2) | 13312 | 45,3 TFLOPs | 90,5 TFLOPs | 362,1 TFLOPs | 362,1 TOPS | 128 GB | 3,2 TB/s |
Il modello MI250, invece, vede alcune unità disabilitate (104 CU attivi) e si ferma a 208 CU e 13.312 stream processor totali. La sua potenza di calcolo scende quindi a 45,3 TFLOPs con calcoli vettoriali FP32/64 e a 362,1 TOPS con INT4/8. In realtà, un GDC completo offre 112 unità (per un totale di 224 sull’intera GPU), ma per questioni di rese produttive AMD ne ha disabilitati alcuni a seconda dell’acceleratore. Per riferimento, una Instinct MI100, la top di gamma di precedente generazione, prevede 120 CU per un totale di 7680 stream processor e 32 GB di memoria HBM2 a 1,2 TB/s.

Ogni GDC è dotato anche di due Video Codec Next (VCN) per codifica e decodifica dei flussi di dati (immagini e video) in entrata e uscita. Il VCN supporta H.264/AVC, HEVC, VP9 e JPEG per la decodifica e H.264/AVC e HEVC per la codifica.

AMD ha rivisto anche la gerarchia della memoria: ogni GCD offre 8 MB di cache L2 con una bandwidth raddoppiata a 128 byte per clock. L’architettura CDNA 2 integra inoltre fino a 880 Matrix Core di seconda generazione per accelerare operazioni tra matrici FP64 e FP32, fornendo fino a quattro volte la potenza di picco teorica FP64 rispetto alle GPU di generazione precedente. A tutto questo si aggiungono 64 GB di memoria HBM2E per GCD, per un totale di 128 GB di memoria HBM2E a 3,2 TB/s.
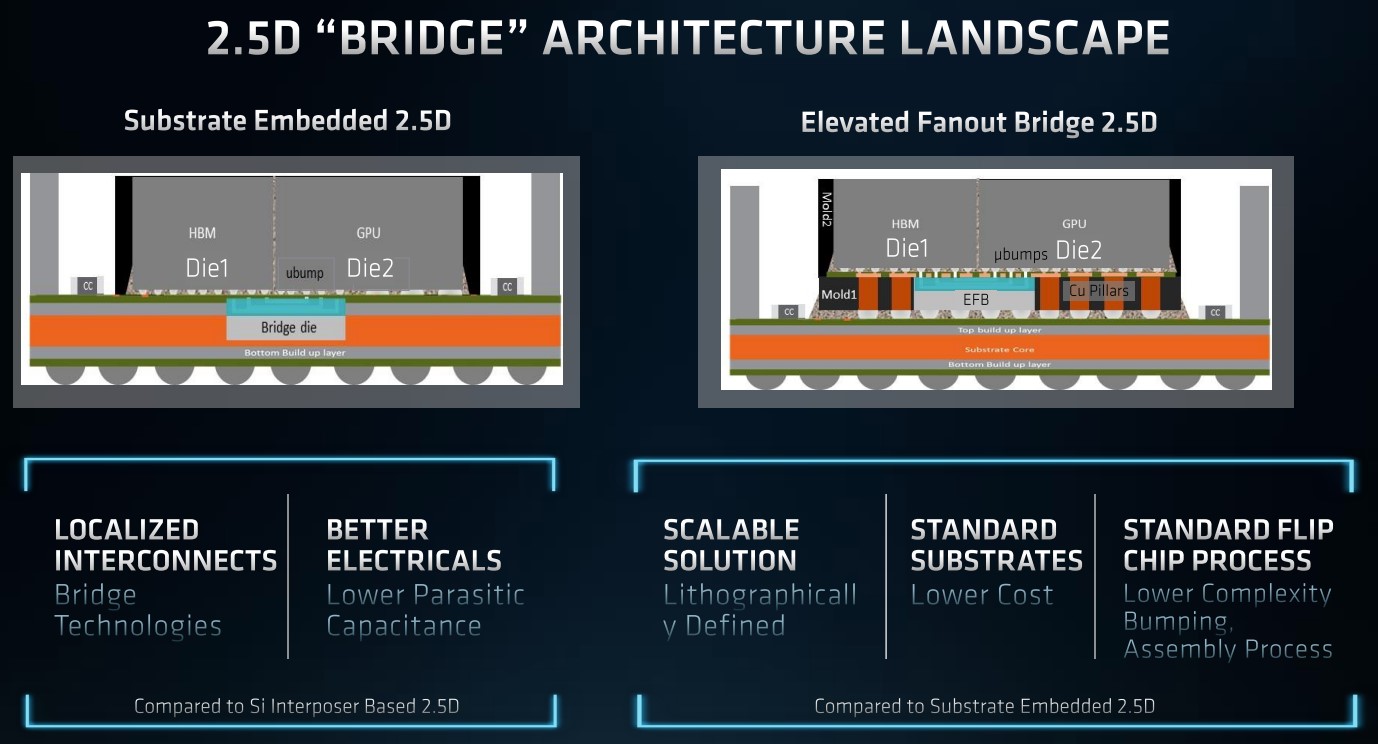
Realizzare una GPU multi-die ha richiesto ad AMD di approntare una nuova tecnologia chiamata 2.5D Elevated Fanout Bridge (EFB) che permette di avere l’80% di core in più e 2,7 volte la bandwidth di memoria delle GPU AMD precedenti, il tutto usando substrati standard.
Un altro tassello per realizzare sistemi come Frontier è la terza generazione della tecnologia di interconnessione Infinity Fabric: un massimo di 8 collegamenti permettono agli acceleratori di scambiarsi dati ad altissima velocità (fino a 800 GB/s) con le CPU EPYC e gli altri acceleratori Instinct presenti nel “nodo di calcolo”, offrendo una memoria unificata e coerente tra CPU e GPU per un throughput al massimo livello.

L’interconnessione Infinity Fabric di terza generazione è usata anche all’interno della GPU per collegare i GCD tra loro con una bandwidth bidirezionale di 400 GB/s e questo permette al sistema di vedere la GPU come se fosse una sola nonostante vi siano due die. A completare il tutto la piattaforma open ROCm 5.0 per dare a scienziati e ricercatori il massimo del supporto in termini di sviluppo, al fine di ottimizzare il loro codice per la nuova architettura CDNA 2.

AMD Instinct MI250X e MI250 debuttano formato nel OCP Accelerator Module (OAM), ma arriverà anche una scheda chiamata Instinct MI210 in formato PCI Express per i server generici.

Il modello MI250X è attualmente disponibile da HPE tramite il supercomputer Cray EX, mentre bisognerà attendere il Q1 2022 per vederla sui sistemi di ASUS, ATOS, Dell Technologies, Gigabyte, Hewlett Packard Enterprise (HPE), Lenovo e Supermicro.
Fonte: http://feeds.hwupgrade.it/